- exception : custom exception 들과 exception handler 로 이루어져 있다.
- service : service 들로 이루어져 있다.
이렇게 디렉토리 구조를 구성하면, 모든 파일을 한 눈에 보기 용이하고 구조가 단순하기에 이해하기 쉽다.
그러나 Entity의 종류가 계속해서 늘어나고 그에 맞춰 Jpa repository 가 늘어나면서, 모든 요청을 한 controller와 service 에서 다룰 수 없기 때문에 마찬가지로 늘어나면서 한 디렉토리 내에 너무 많은 종류의 controller, service 등의 쌓이게 되어
파일을 찾아내기가 곤란해졌다.
그리고 무엇보다 협업을 하다보니 이러한 불편한 점이 두드러졌다. 모두들 같은 디렉토리에서 파일을 수정하다보니, 거리낌 없이 다른 파일을 수정하게 되고, 이는 code conflict 로 이어졌다.
그러한 와중에 새로운 디렉토리 구조를 찾아보게 되었고, 마침 발견하게 된 것이 도메인형 디렉토리 구조였다.
도메인이라는 단어는 어떤걸까? DDD (Domain Driven Design) 와 관련이 있다.
DDD (Domain Driven Design)
소프트웨어 개발 방법론 중 하나로 도메인에 집중하는 소프트웨어 설계법 이다. 여기서 말하는 도메인이란, 개발자들만 필요하고 이해할 수 있는 영역이 아닌 사용자도 이해할 수 있는, 유비쿼터스(ubiquitous)하게 정의되는, 해결 해야하는 문제의 영역을 의미한다.
실제로 예를 들자면,
학교 축제 웹페이지라면
1) 축제 부스 관련 정보를 검색 및 조회 2) 부스 페이지에 댓글 작성 및 삭제 등등...
학교 도서관 예약 시스템이라면
1) 기존 예약 조회 및 예약 진행 2) 사용자 맞춤 기능(마이페이지, 로그인 등) 등등...
이렇게 해결 해야하는 문제 즉, 구현해야하는 기능들을 종류별로 나누고 그 기능들을 우선적으로 생각하면서 소프트웨어를 개발하는 방법론이다. DDD 를 지향하는 개발 방법은 여러가지가 있을 것이다.
예를 들면 ERD를 먼저 짜는 게 아니고, Controller 부터 Service 그 다음 Repository 까지 개발하는 방식이 있다. 이러한 방식은 프론트 팀원들에게 API 명세서를 빠르게 던져줄 수도 있고, 먼저 그려진 ERD에 의해 개발자의 사고가 제한되는 것을 막을 수 있다고 한다.
하여튼 그래서 DDD 의 주요 특징 중 하나가 Bounded Context 이다.
Bounded Context: A description of a boundary (typically a subsystem, or the work of a specific team) within which a particular model is defined and applicable. Every domain model lives in precisely one BC, and a BC contains precisely one domain model. BC is a specific responsibility, with explicit boundaries that separate it from other parts of the system.
별도의 의존관계가 없이 Singleton 으로 동작하는 방식이고 SpringBoot Application 을 생성하면 자동으로 해결이 된다.
2번 Controller, Service, Repository
Controller-Service-Repository 구조안에 있는 객체들이다. 마찬가지로 Singleton 객체임을 보장한다. @Service, @Controller, @Repository 등의 어노테이션이 스프링 컨테이너가 이를 스프링 빈으로 감지하게하기 때문이다.
서로 호출하는 방향이 정해져 있다. (controller -> service -> repository) 서로 연결되어 있기에 그 생명주기를 같이한다.
(서버의 시작과 끝 스프링 컨테이너에 의해 생성, 소멸)
controller - service 참조 예시
그들사이 연결 즉, 의존이 완고하고, 변할 일이 잘 없다. 그렇기에 내부 의존 관계에 대해 private 지정자를 설정하여 외부에서 접근할 수 없게하고, final 을 통해서 상수로 지정해 절대 변경하지 못하도록 하여 안정성을 보장한다.
Controller-Service-Repository 이 구조는 어떻게 보면 정말 절대적인 구조이고, 절대 변경되지 않아야하는 만큼 private 과 final 로 구조 사이 연결을 견고히 할 수 있는 것이다. final 을 통해 절대 불변의 객체라는 것을 명시하면 가독성도, 객체지향설계에도, 성능적으로도 이점이 있다! 변할 가능성이 없으니 메모리 할당을 미리 배제시킬 수 있기 때문이다.
@RequiredArgsConstructor 는 Lombok 프로젝트의 기능 중 하나로, 해당 어노테이션이 붙은 객체의 required argument 가 들어간 생성자를 만들어준다. 그럼 스프링 컨테이너가
Required arguments are final fields and fields with constraints such as @NonNull
document 를 통해서도 알 수 있듯이 Required Argument란 final 이 붙어있거나, @NonNull 이 붙은 필드값을 의미하고 그것들을 담고있는 그야말로 절대불변의 필수적인 필드값을 생성하는 생성자를 만드는 것이다. 이러면 별도로 @Autowired 어노테이션이나 생성자를 만들어 줄 필요가 없다.
접근 지정자의 경우 기본적으로 public 이다. 그러나 해당 객체는 로직 내에서 생성자가 사용될 일이 없이, 스프링 컨테이너에 의해 싱글톤(singleton)객체로 관리된다. 그렇기 때문에 access 레벨을 protected 으로 설정하여 객체의 무분별한 생성을 막아줘야한다. (어 근데 private 은 안된다. 왜 그렇지...)
access 속성을 AccessLevel.PROTECTED 로 설정해주어 객체를 관리한다.
3번 DTO, Model
DTO 와 Model 서버 계층에서 데이터를 저장하고 처리하기 위한 객체이다. 주로 Service 내에서 Entity 의 정보를 저장하고 이를 비즈니스 로직에 맞게 가공하여 Controller에서 반환하는 역할을 수행한다.
해당 객체들은 Service 객체에 의해 생성될 것이다. singleton 도 아니다. Builder 패턴을 주로 사용한다.
Builder 패턴?
빌더 패턴은 자료가 워낙 많아 간단히 설명하면, 객체의 생성 시 객체 내 필드 중 원하는 필드만 쏙쏙 골라 이를 매개변수로 받아 객체를 생성하는 디자인 패턴이다. 장점은 유연하게 객체를 생성할 수 있고, 내부 필드값을 주입할 때 그 순서를 모르더라도 메서드 명으로 통해 명시적으로 어떤 필드 값을 주입하는지 알 수 있고, 순서도 알 필요가 없다는 점이다.
그럼 왜 DTO에 Builder 를 쓰는 걸까? DTO 는 주로 Entity의 정보들을 받아 재구성하여 비즈니스 로직의 중간단계, 서버 응답의 최종단계 등 다양한 용도로 사용된다. 필요에 따라 사용하는 데이터의 값이 Entity와 대부분 완전 일치하지 않기에 Entity 의 값들을 DTO에 옯길 때
그런데 한 가지 의문이 든다. 빌더 패턴을 사용하지 않고, DTO를 생성한 다음, setter 메서드를 통해서 내부 필드 값들을 선택적으로 초기화해주면 되는거 아닐까? 논리적으로는 다를 게 없다.
허나 setter 메서드의 경우 객체가 생성되고 나서 또 다른 객체를 주입받아 내부 필드값으로 지정하는 방식이다. 그런데 이러한 방식에 대해서 객체의 불변성, 도메인 영역과 응용 영역의 구분이 모호해지는 등 다양한 문제가 있다. getter 메서드 또한 내부 참조관련해서 문제가 있다고 하니 쓰는 것을 지양해야한다고 한다. 이건 나중에 한번 다시 봐야될 듯 하다.
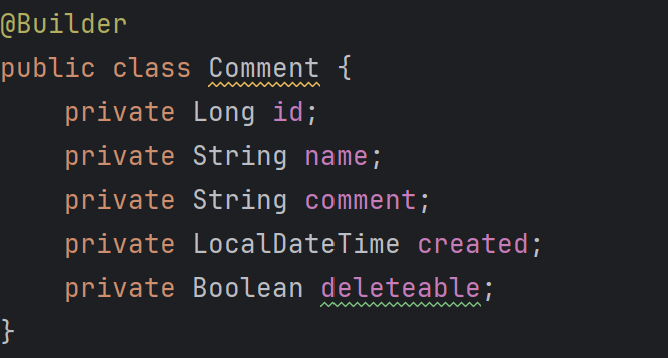
필드 값이 2개 있는 DTO에다 빌더 패턴을 직접 구현해보자!
CommentRequest 의 필드값
내부에 Builder 객체 구현
Builder 객체 내부에 CommentRequest 의 필드 값을 복사해준 다음, 각 필드 값마다 초기화 메서드를 만들어준다. 반환 값은 초기화 다음 Builder 자기 자신을 반환함으로써, 초기화 과정을 계속해서 이어나간다.
초기화가 끝났다면 Builder 자기 자신을 CommentRequest 의 생성자로 넘겨줌으로써 생성 과정이 끝나게된다.
Builder 패턴 의 시작과 끝
CommentRequest 내부에 builder 메서드로 생성과정을 시작하고, Builder 를 매개변수로 받는 생성자를 통해 객체를 생성하면서 끝난다.
전체적인 과정을 살펴보면 Builder 라는 객체 생성을 위해 그를 복사한 임시 객체를 만들고, 그 객체를 통해 필드 값을 초기화 한 다음 그렇게 입맛대로 초기화된 임시객체를 넘겨주어 진짜 객체를 생성한다.
아 근데 너무 귀찮다 이걸 일일이 다 구현한다고? 그래서 lombok 에서 @Builder 어노테이션을 만들어줬다.
Builder 패턴 class 상위에 넣기Builder 패턴 생성자 상위에 넣기
class 의 상위에 넣어주거나, 직접 생성자를 만들어서 해당 메서드에 넣어줘도 된다. 후자의 장점은 원하는 필드 값만 Builder를 통해 초기화 시켜줄 수 있다는 점이다. 그런데 그게 큰 장점이 있는 지는 모르겠다. 코드의 길이가 길어지긴 하겠지만, 애초에 빌더 패턴의 장점이 객체의 유연한 생성인데, 모든 필드 값을 후보에 넣는 것이 그 장점을 이용하는 것이라 생각한다. 애초에 DTO 라면, Entity의 id 값 등 건드릴 필요가 없는 값들이 있는 것도 아니고 모든 값들이 필요에 의해서 정의 되었을 가능성이 크기 때문이다. 그리고 AllArgsConstructor 사용을 막을 수 있는 이점도 있는데 이 내용은 밑에서 다시 다루겠다.
* RequestBody 나 ResponseBody 에 쓰이는 DTO 객체는 무조건 @Getter 를 붙여야한다. (추후에 포스팅 예정)
4번 Entity (Jpa)
Entity 는 Jpa에서 지원하는 객체로 ORM을 지원할 수 있게 해주는 객체이다. 자세한 내용은 추후에 포스팅 할 예정이다.
하여튼 Jpa에서는 RDB 의 특징 중 하나인 연관관계를 지원하는데, 연관관계가 설정된 객체를 불러올 때 전략 중 하나로,
지연 로딩 (Lazy Loading) 을 지원한다.
지연로딩?
Lazy Loading
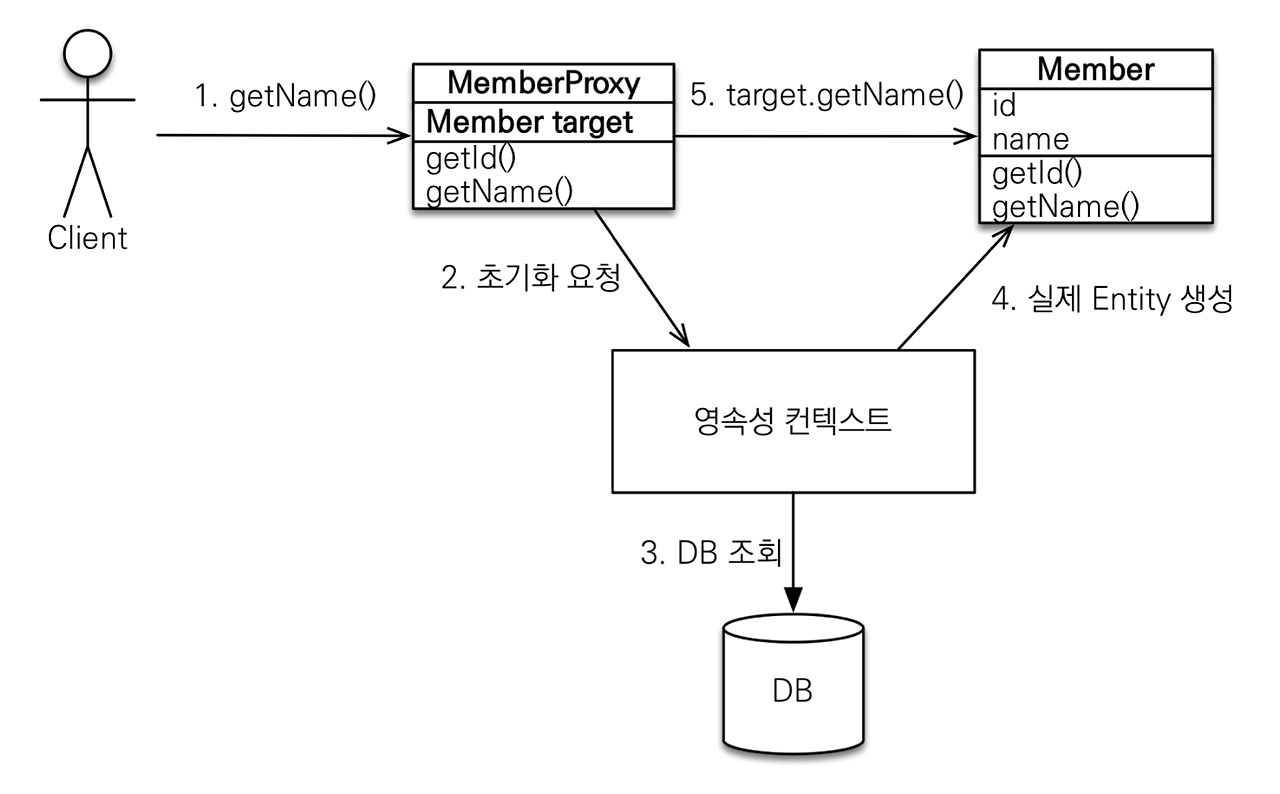
지연로딩이란 어떤 객체를 불러왔을 때 그와 연관관계에 있는 객체를 한 번에 다 불러오는 게 아니고 프록시 객체를 만든 다음에 후에 그 객체를 실제로 참조하고자 할 때 영속성 컨텍스트가 프록시 객체를 기준으로 DB에서 해당 data를 불러와 실제 Entity 를 생성하는 데이터 로딩 방식이다.
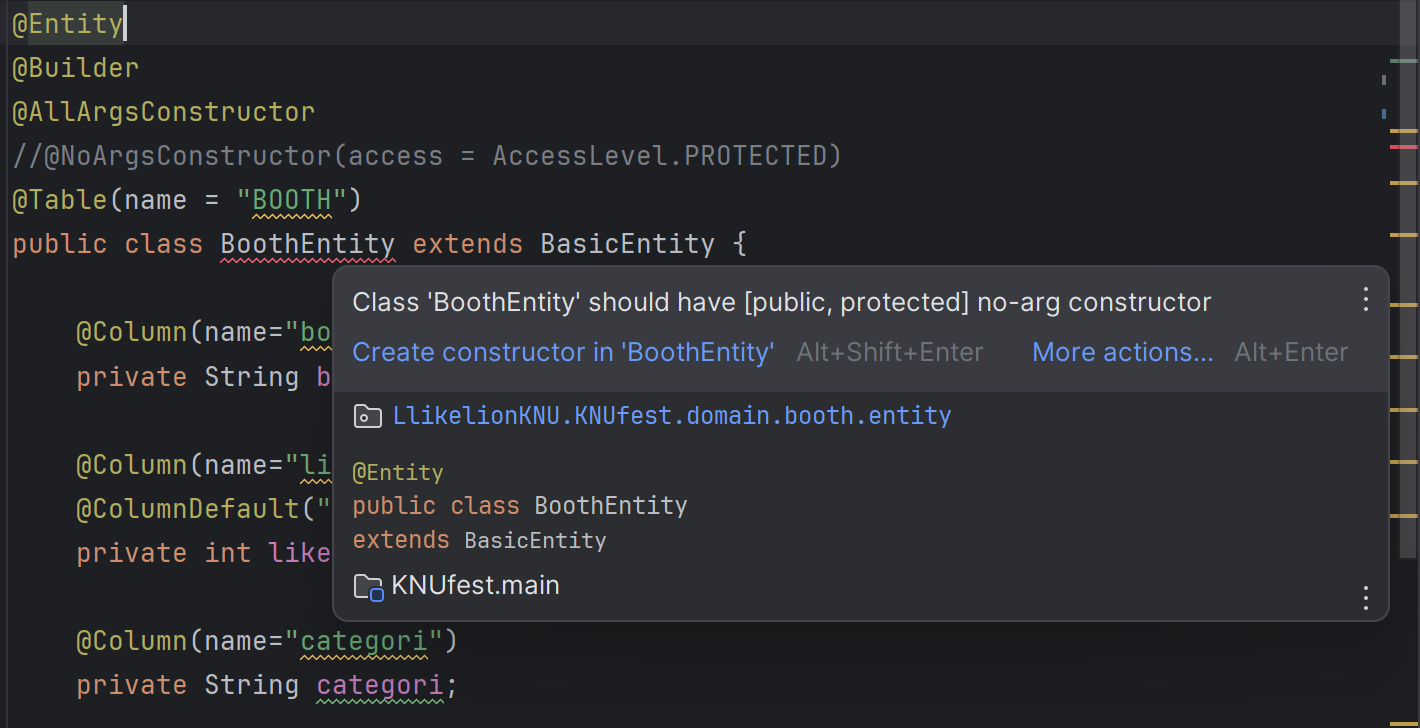
암튼 그래서 이때 프록시 객체를 생성하기 위해서는 기본생성자 즉 아무 필드값도 주입받지 않는 생성자가 필요하다.
기본 생성자가 없는 경우 오류메시지
@NoArgsConstructor 어노테이션은 기본생성자를 자동으로 만들어주는 Lombok 의 기능이다.
주석 처리하니까 public 이나 protected 지정자를 가진 기본생성자가 무조건 필요하다고 한다. 영속성 컨텍스트가 프록시 객체를 생성할 때 쓰인다는 것은 알겠는데 왜 protected?로 해줘야 할까?
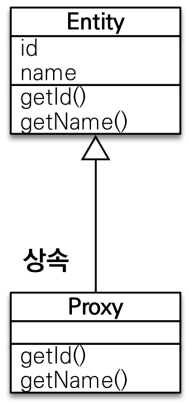
entity 와 proxy 의 구조
영속성 컨텍스트가 proxy 를 생성할 때 기존의 Entity 를 상속한 객체를 생성하기 때문에 protected 를 통해서 자기 자신이나 자신을 상속한 객체만 생성자에 접근할 수 있도록 해줘야한다.
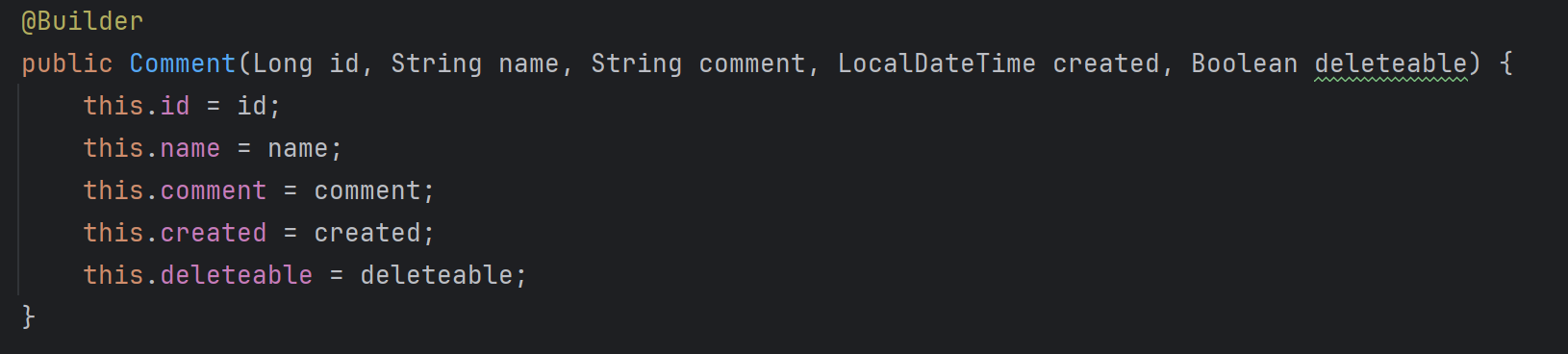
여기서도 빌더 패턴을 쓸 것이다. 근데 주의할 점이 있다. 앞서 우리는 @NoArgsConstructor 를 통해 프록시 객체의 생성자를 만들어줬다. @Builder 어노테이션은 생성자가 없을 경우 자동으로 모든 필드가 들어간 생성자를 생성해준다.
Finally, applying @Builder to a class is as if you added @AllArgsConstructor(access = AccessLevel.PACKAGE) to the class and applied the @Builder annotation to this all-args-constructor. This only works if you haven't written any explicit constructors yourself or allowed lombok to create one such as with @NoArgsConstructor. If you do have an explicit constructor, put the @Builder annotation on the constructor instead of on the class.
공식 문서에서도 나와있듯이 생성자를 명시적으로 선언하지 않은경우 @AllArgsConstructor 어노테이션을 자동으로 적용해주고, 만약에 @NoArgsConstructor 와 같이 생성자를 생성해줄 경우, @Builder 어노테이션을 직접 생성자 메서드 위에다가 달아주어야 한다.
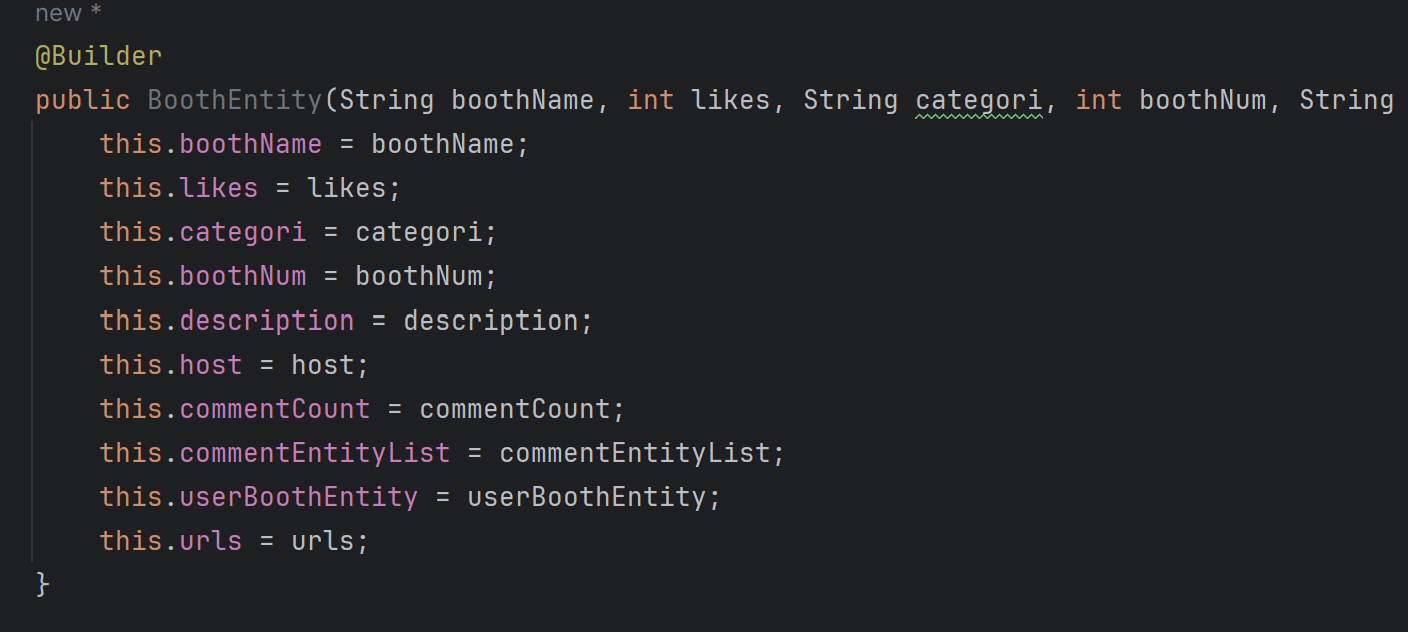
생성자에다가 직접 Builder 를 붙여준 모습
이런 식으로 직접 생성자를 만들어 준 다음 @Builder 를 붙여주면 Entity에 안전하게 빌더패턴을 적용할 수 있다.
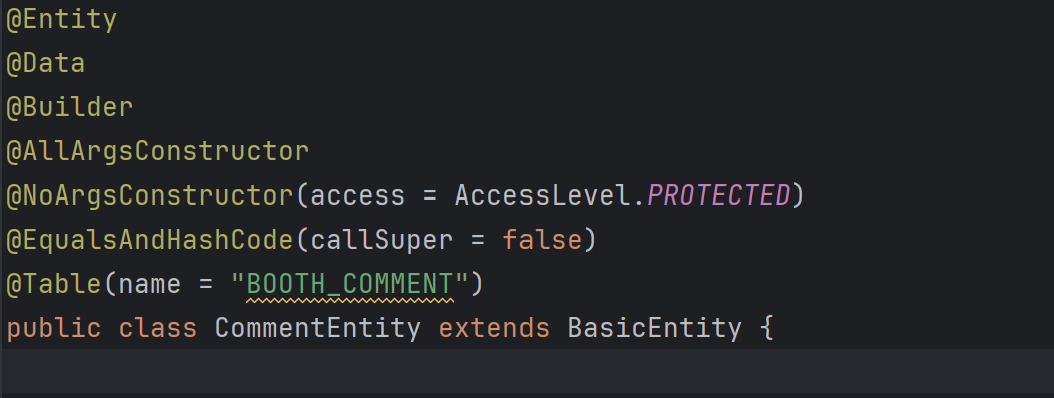
class 위에다가 덕지덕지 붙여버리기
물론 이렇게 class 위에다가 덕지덕지 붙여도 큰 문제는 아니겠지만 일단 보기 너무 안좋고 무엇보다 AllArgsConstructor 사용을 지양하는 트렌드가 있다고 한다. 왜냐? 모든 필드가 추가된 생성자는 매개변수의 순서를 바꿔 넣을 수 도 있기 때문이라고 하는데... 크게 납득이 되진 못한다. 허나 가독성 측면에서도 그렇고 공식 문서에서도 생성자에다 직접 Builder 를 붙여주라고 하기에 나는 앞으로 계속 그렇게 할 것 같다.
정리를 해보면
- Service, Controller 등은 @RequiredArgsConstructor, 접근 레벨은 protected 로 설정
- DTO 는 Builder 패턴을 적용 그냥 @Builder 어노테이션 붙여주기
- Entity 는 Jpa의 프록시 객체 생성을 위한 @NoArgsConstructor(access=AccessLevel.PROTECTED), 직접 생성자를 만든 다음 @Builder 어노테이션을 붙여주기