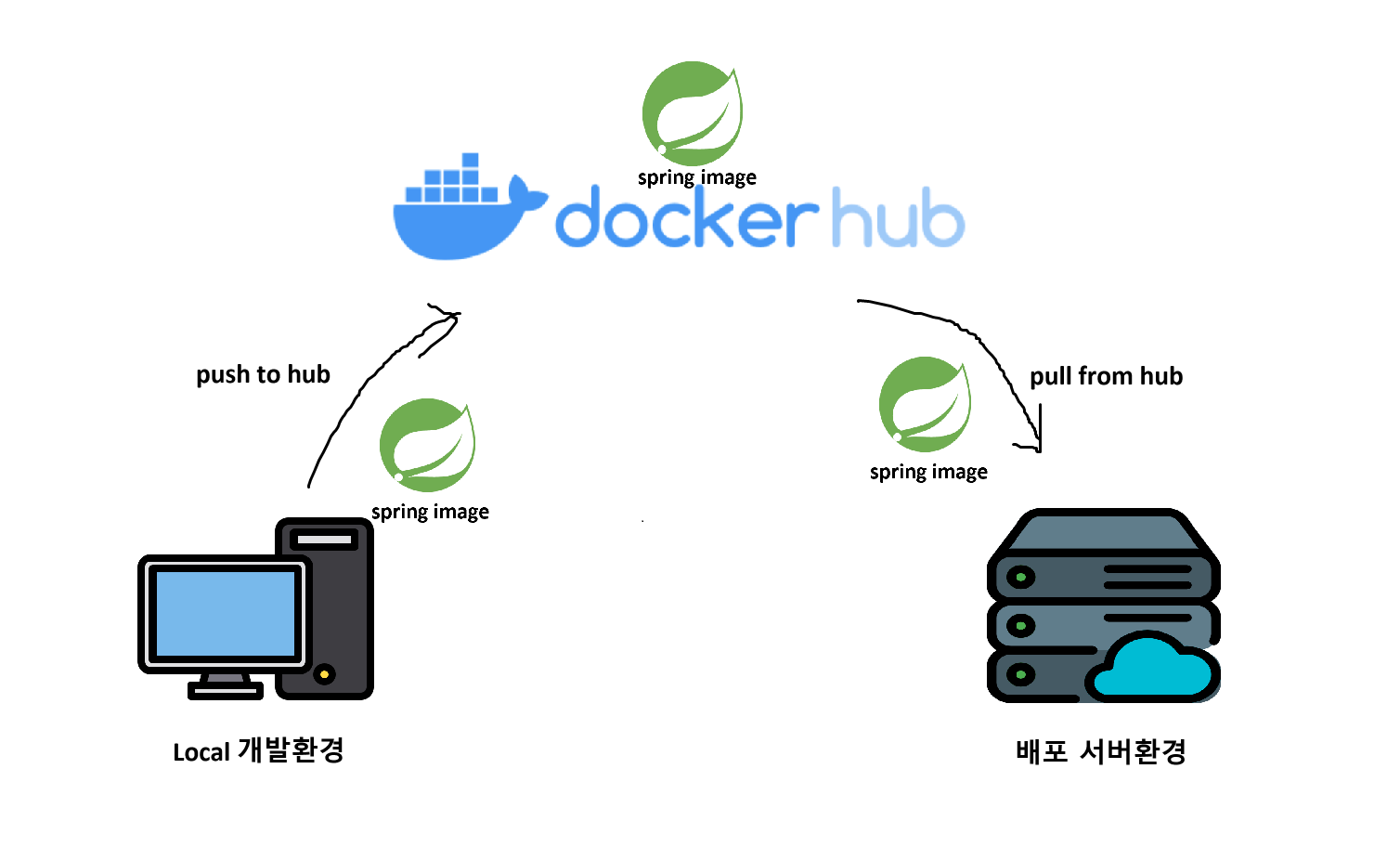
별도의 의존관계가 없이 Singleton 으로 동작하는 방식이고 SpringBoot Application 을 생성하면 자동으로 해결이 된다.
2번 Controller, Service, Repository
Controller-Service-Repository 구조안에 있는 객체들이다. 마찬가지로 Singleton 객체임을 보장한다. @Service, @Controller, @Repository 등의 어노테이션이 스프링 컨테이너가 이를 스프링 빈으로 감지하게하기 때문이다.
서로 호출하는 방향이 정해져 있다. (controller -> service -> repository) 서로 연결되어 있기에 그 생명주기를 같이한다.
(서버의 시작과 끝 스프링 컨테이너에 의해 생성, 소멸)
controller - service 참조 예시
그들사이 연결 즉, 의존이 완고하고, 변할 일이 잘 없다. 그렇기에 내부 의존 관계에 대해 private 지정자를 설정하여 외부에서 접근할 수 없게하고, final 을 통해서 상수로 지정해 절대 변경하지 못하도록 하여 안정성을 보장한다.
Controller-Service-Repository 이 구조는 어떻게 보면 정말 절대적인 구조이고, 절대 변경되지 않아야하는 만큼 private 과 final 로 구조 사이 연결을 견고히 할 수 있는 것이다. final 을 통해 절대 불변의 객체라는 것을 명시하면 가독성도, 객체지향설계에도, 성능적으로도 이점이 있다! 변할 가능성이 없으니 메모리 할당을 미리 배제시킬 수 있기 때문이다.
@RequiredArgsConstructor 는 Lombok 프로젝트의 기능 중 하나로, 해당 어노테이션이 붙은 객체의 required argument 가 들어간 생성자를 만들어준다. 그럼 스프링 컨테이너가
Required arguments are final fields and fields with constraints such as @NonNull
document 를 통해서도 알 수 있듯이 Required Argument란 final 이 붙어있거나, @NonNull 이 붙은 필드값을 의미하고 그것들을 담고있는 그야말로 절대불변의 필수적인 필드값을 생성하는 생성자를 만드는 것이다. 이러면 별도로 @Autowired 어노테이션이나 생성자를 만들어 줄 필요가 없다.
접근 지정자의 경우 기본적으로 public 이다. 그러나 해당 객체는 로직 내에서 생성자가 사용될 일이 없이, 스프링 컨테이너에 의해 싱글톤(singleton)객체로 관리된다. 그렇기 때문에 access 레벨을 protected 으로 설정하여 객체의 무분별한 생성을 막아줘야한다. (어 근데 private 은 안된다. 왜 그렇지...)
access 속성을 AccessLevel.PROTECTED 로 설정해주어 객체를 관리한다.
3번 DTO, Model
DTO 와 Model 서버 계층에서 데이터를 저장하고 처리하기 위한 객체이다. 주로 Service 내에서 Entity 의 정보를 저장하고 이를 비즈니스 로직에 맞게 가공하여 Controller에서 반환하는 역할을 수행한다.
해당 객체들은 Service 객체에 의해 생성될 것이다. singleton 도 아니다. Builder 패턴을 주로 사용한다.
Builder 패턴?
빌더 패턴은 자료가 워낙 많아 간단히 설명하면, 객체의 생성 시 객체 내 필드 중 원하는 필드만 쏙쏙 골라 이를 매개변수로 받아 객체를 생성하는 디자인 패턴이다. 장점은 유연하게 객체를 생성할 수 있고, 내부 필드값을 주입할 때 그 순서를 모르더라도 메서드 명으로 통해 명시적으로 어떤 필드 값을 주입하는지 알 수 있고, 순서도 알 필요가 없다는 점이다.
그럼 왜 DTO에 Builder 를 쓰는 걸까? DTO 는 주로 Entity의 정보들을 받아 재구성하여 비즈니스 로직의 중간단계, 서버 응답의 최종단계 등 다양한 용도로 사용된다. 필요에 따라 사용하는 데이터의 값이 Entity와 대부분 완전 일치하지 않기에 Entity 의 값들을 DTO에 옯길 때
그런데 한 가지 의문이 든다. 빌더 패턴을 사용하지 않고, DTO를 생성한 다음, setter 메서드를 통해서 내부 필드 값들을 선택적으로 초기화해주면 되는거 아닐까? 논리적으로는 다를 게 없다.
허나 setter 메서드의 경우 객체가 생성되고 나서 또 다른 객체를 주입받아 내부 필드값으로 지정하는 방식이다. 그런데 이러한 방식에 대해서 객체의 불변성, 도메인 영역과 응용 영역의 구분이 모호해지는 등 다양한 문제가 있다. getter 메서드 또한 내부 참조관련해서 문제가 있다고 하니 쓰는 것을 지양해야한다고 한다. 이건 나중에 한번 다시 봐야될 듯 하다.
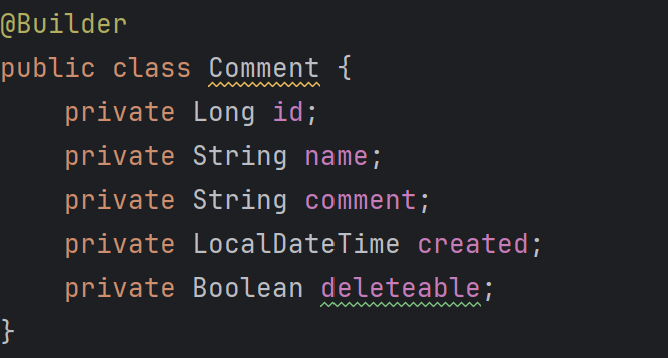
필드 값이 2개 있는 DTO에다 빌더 패턴을 직접 구현해보자!
CommentRequest 의 필드값
내부에 Builder 객체 구현
Builder 객체 내부에 CommentRequest 의 필드 값을 복사해준 다음, 각 필드 값마다 초기화 메서드를 만들어준다. 반환 값은 초기화 다음 Builder 자기 자신을 반환함으로써, 초기화 과정을 계속해서 이어나간다.
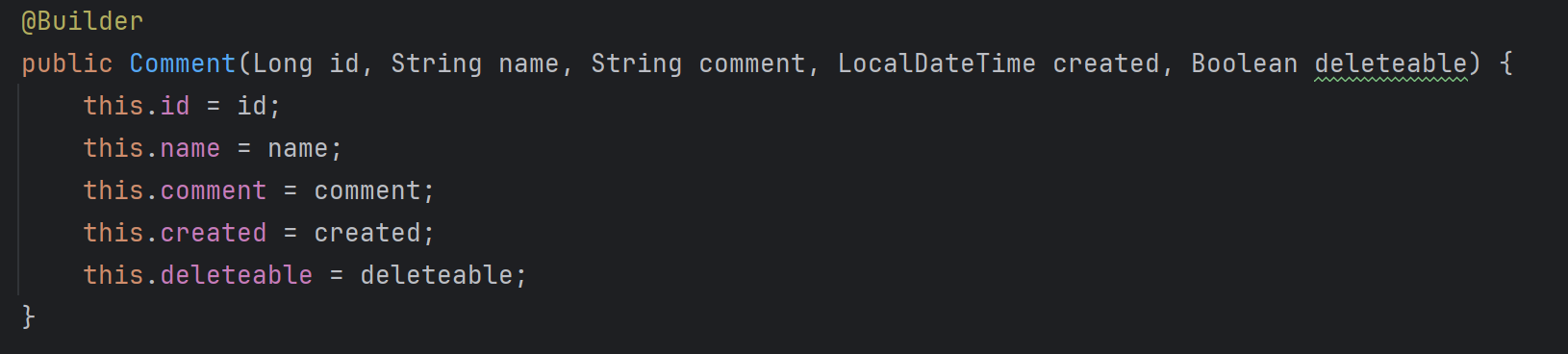
초기화가 끝났다면 Builder 자기 자신을 CommentRequest 의 생성자로 넘겨줌으로써 생성 과정이 끝나게된다.
Builder 패턴 의 시작과 끝
CommentRequest 내부에 builder 메서드로 생성과정을 시작하고, Builder 를 매개변수로 받는 생성자를 통해 객체를 생성하면서 끝난다.
전체적인 과정을 살펴보면 Builder 라는 객체 생성을 위해 그를 복사한 임시 객체를 만들고, 그 객체를 통해 필드 값을 초기화 한 다음 그렇게 입맛대로 초기화된 임시객체를 넘겨주어 진짜 객체를 생성한다.
아 근데 너무 귀찮다 이걸 일일이 다 구현한다고? 그래서 lombok 에서 @Builder 어노테이션을 만들어줬다.
Builder 패턴 class 상위에 넣기Builder 패턴 생성자 상위에 넣기
class 의 상위에 넣어주거나, 직접 생성자를 만들어서 해당 메서드에 넣어줘도 된다. 후자의 장점은 원하는 필드 값만 Builder를 통해 초기화 시켜줄 수 있다는 점이다. 그런데 그게 큰 장점이 있는 지는 모르겠다. 코드의 길이가 길어지긴 하겠지만, 애초에 빌더 패턴의 장점이 객체의 유연한 생성인데, 모든 필드 값을 후보에 넣는 것이 그 장점을 이용하는 것이라 생각한다. 애초에 DTO 라면, Entity의 id 값 등 건드릴 필요가 없는 값들이 있는 것도 아니고 모든 값들이 필요에 의해서 정의 되었을 가능성이 크기 때문이다. 그리고 AllArgsConstructor 사용을 막을 수 있는 이점도 있는데 이 내용은 밑에서 다시 다루겠다.
* RequestBody 나 ResponseBody 에 쓰이는 DTO 객체는 무조건 @Getter 를 붙여야한다. (추후에 포스팅 예정)
4번 Entity (Jpa)
Entity 는 Jpa에서 지원하는 객체로 ORM을 지원할 수 있게 해주는 객체이다. 자세한 내용은 추후에 포스팅 할 예정이다.
하여튼 Jpa에서는 RDB 의 특징 중 하나인 연관관계를 지원하는데, 연관관계가 설정된 객체를 불러올 때 전략 중 하나로,
지연 로딩 (Lazy Loading) 을 지원한다.
지연로딩?
Lazy Loading
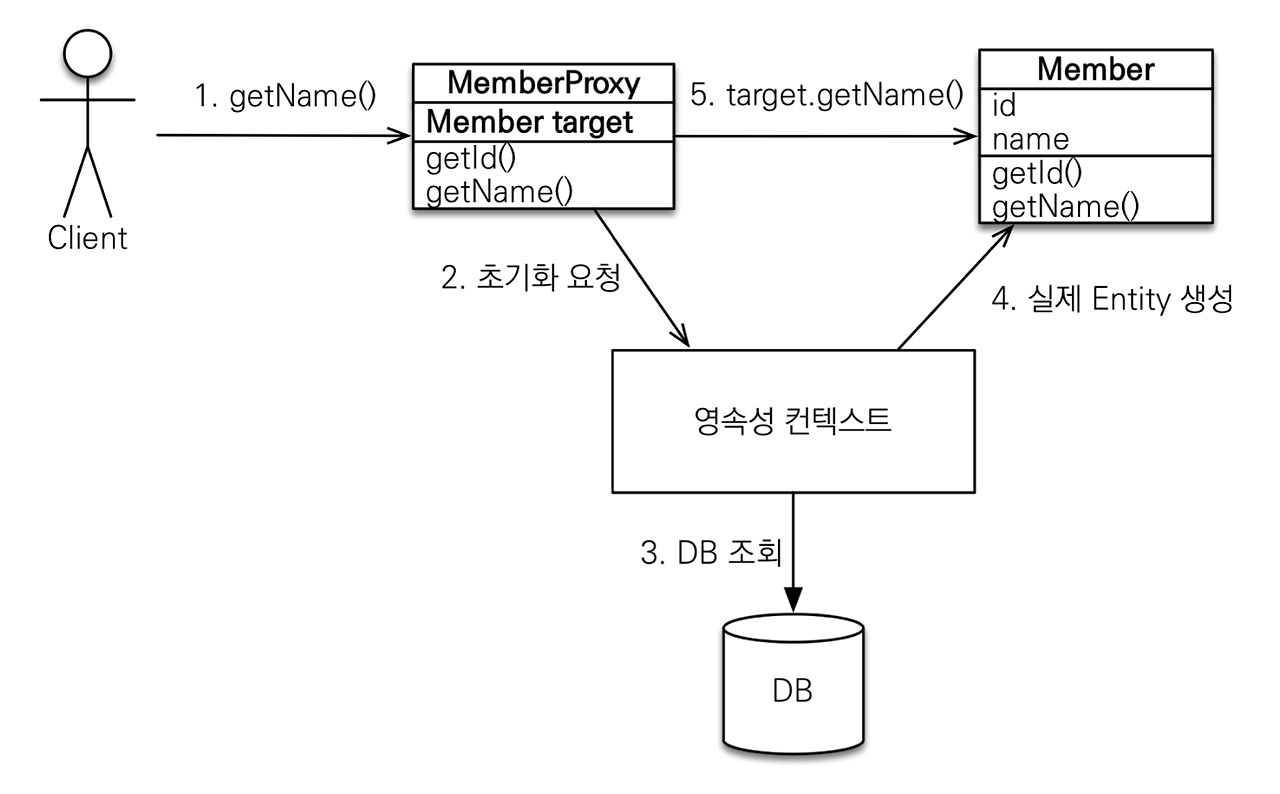
지연로딩이란 어떤 객체를 불러왔을 때 그와 연관관계에 있는 객체를 한 번에 다 불러오는 게 아니고 프록시 객체를 만든 다음에 후에 그 객체를 실제로 참조하고자 할 때 영속성 컨텍스트가 프록시 객체를 기준으로 DB에서 해당 data를 불러와 실제 Entity 를 생성하는 데이터 로딩 방식이다.
암튼 그래서 이때 프록시 객체를 생성하기 위해서는 기본생성자 즉 아무 필드값도 주입받지 않는 생성자가 필요하다.
기본 생성자가 없는 경우 오류메시지
@NoArgsConstructor 어노테이션은 기본생성자를 자동으로 만들어주는 Lombok 의 기능이다.
주석 처리하니까 public 이나 protected 지정자를 가진 기본생성자가 무조건 필요하다고 한다. 영속성 컨텍스트가 프록시 객체를 생성할 때 쓰인다는 것은 알겠는데 왜 protected?로 해줘야 할까?
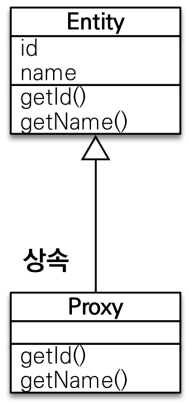
entity 와 proxy 의 구조
영속성 컨텍스트가 proxy 를 생성할 때 기존의 Entity 를 상속한 객체를 생성하기 때문에 protected 를 통해서 자기 자신이나 자신을 상속한 객체만 생성자에 접근할 수 있도록 해줘야한다.
여기서도 빌더 패턴을 쓸 것이다. 근데 주의할 점이 있다. 앞서 우리는 @NoArgsConstructor 를 통해 프록시 객체의 생성자를 만들어줬다. @Builder 어노테이션은 생성자가 없을 경우 자동으로 모든 필드가 들어간 생성자를 생성해준다.
Finally, applying @Builder to a class is as if you added @AllArgsConstructor(access = AccessLevel.PACKAGE) to the class and applied the @Builder annotation to this all-args-constructor. This only works if you haven't written any explicit constructors yourself or allowed lombok to create one such as with @NoArgsConstructor. If you do have an explicit constructor, put the @Builder annotation on the constructor instead of on the class.
공식 문서에서도 나와있듯이 생성자를 명시적으로 선언하지 않은경우 @AllArgsConstructor 어노테이션을 자동으로 적용해주고, 만약에 @NoArgsConstructor 와 같이 생성자를 생성해줄 경우, @Builder 어노테이션을 직접 생성자 메서드 위에다가 달아주어야 한다.
생성자에다가 직접 Builder 를 붙여준 모습
이런 식으로 직접 생성자를 만들어 준 다음 @Builder 를 붙여주면 Entity에 안전하게 빌더패턴을 적용할 수 있다.
class 위에다가 덕지덕지 붙여버리기
물론 이렇게 class 위에다가 덕지덕지 붙여도 큰 문제는 아니겠지만 일단 보기 너무 안좋고 무엇보다 AllArgsConstructor 사용을 지양하는 트렌드가 있다고 한다. 왜냐? 모든 필드가 추가된 생성자는 매개변수의 순서를 바꿔 넣을 수 도 있기 때문이라고 하는데... 크게 납득이 되진 못한다. 허나 가독성 측면에서도 그렇고 공식 문서에서도 생성자에다 직접 Builder 를 붙여주라고 하기에 나는 앞으로 계속 그렇게 할 것 같다.
정리를 해보면
- Service, Controller 등은 @RequiredArgsConstructor, 접근 레벨은 protected 로 설정
- DTO 는 Builder 패턴을 적용 그냥 @Builder 어노테이션 붙여주기
- Entity 는 Jpa의 프록시 객체 생성을 위한 @NoArgsConstructor(access=AccessLevel.PROTECTED), 직접 생성자를 만든 다음 @Builder 어노테이션을 붙여주기
2024 경북대학교 대동제 '하푸르나' 안내 웹사이트를 개발하면서, 출시 하루 전이었다. 메인화면에서 축제가 종료될 때 까지 얼마나 남았는지 알려주는 기능이 있었기에 현재 서버 시간을 응답하는 api가 필요했다.
그래서 아래와 같이 api 를 작성하였다.
현재 시간을 응답하는 api
Instant?
java 8 버전부터 java.time 패키지가 등장하면서, java 애플리케이션에서 시간을 다루기 좀 더 용이해졌고
Instant 는 기존에 사용하던 Date 객체를 대체하기 위해서 만들어졌다. Date 객체는 UNIX TimeStamp를 대체하기 위해 만들어졌는데 타임스탬프(TimeStamp)는 현재 시각을 나타내는 문자열로써 사람이 이해하기 보다는 기계가 이해하기 쉽다. 이를 사람이 보기 쉽게 바꾸려면 format 객체를 사용해야한다. 어쨌든 Instant 는 현재 시각을 나타내는 기능의 객체이며, UTC time 을 사용한다. 우리가 일반적으로 사용하는 단위는 영국 그리니치 천문대를 기준으로 한 GMT 시간대인데, 소프트웨어 상에서는 자전주기 변화 등의 이슈로 UTC가 보다 정확하기 때문에 UTC를 사용한다고 한다.
UNIX TimeStamp 를 바로 갖다쓰면 되는거 아닌가? 싶은데, 이는 2038년 1월 19일 화요일 까지 표현가능하기 때문에 Instant 가 이를 해결해줄 수 있다고 한다.
( UNIX TimeStamp 는 Unix 운영체제에서 UTC 기준점인 1970년 1월 1일 자정 (= EPOCH 타임) 으로부터 경과한 시간을 저장한 값 )
JVM의 currentTimeMillis
JVM 을 사용해서 System 즉, OS 상에서 UTC time 의 기준점으로 부터 얼마나 시간이 경과했는지를 밀리초 단위로 가져오는 System 패키지의 메서드인 currentTimeMillis 메서드를 사용한다. 이 메서드는 단순히 경과 시간을 단순한 숫자의 배열로 나타내기 때문에 Instant 는 이를 나노초 단위로 변경하여 추가로 저장하고 아래와 같은 format 으로 변경해 반환한다.
2024-07-05T09:53:30.234521Z ==> 2024년 7월 5일 18시 53분 30초 (대한민국 기준)
처음 시간을 나타내기 위해 Instant 를 사용한 이유는 Long 형태를 사용하기 때문에 연산이 빠르고 시간단위가 기존의 밀리초 단위보다 더 정밀한 단위인 나노초 단위를 사용하기 때문에 보다 정확한 시점을 알 수 있다는 장점이 있다고 생각했기 때문이다.
그런데문제가 생겼다.시간이 맞지 않다는 것이었다. 앞서 설명했지만 Instant 의 now는 우리나라의 시차보다 9시간 전을 반환하기 때문에 이를 보정할 필요가 있었다. 그래서 구글링을 해보니 시차를 해결하기 위해서는 Instant 보다 LocalDateTime 을 사용하라는 자료가 많아서 LocalDateTime 을 사용하기로 하였다.
그리고 생각해보면 이번 프로젝트에서 시간을 사용하는 경우는 딱 2가지
1. 단순히 현재 서버 시간을 반환
2. Data가 생성되거나 수정되는 시간을 timestamp 형식으로 저장
결국 비교, 등의 연산이 필요가 없다는 점과, 현재 local 시스템의 시간과 동일한 시간을 사용하는 LocalDateTime을 사용하기위해 코드를 뜯어봤다.
LocalDateTime?
java 8 버전부터 java.time 패키지에 속한 객체이다. 날짜와 시간을 모두 포함하고 있으며 현재 시스템의 system clock에서 시간을 참조하여 반환한다.
system clock을 통해서 현재 시각을 담고있는 Instant
코드를 뜯어보니 결국에 LocalDateTime 또한 Instant 객체를 생성하고 거기에다가 TimeZone 이라는 객체를 추가적으로 담아 반환하는 것이었다. TimeZone이 나타내는 것은 우리가 시간을 다루기위해서 java.time 관련 객체를 사용했을 때 반환하는 시간은 모두 특정 시점을 기준으로 얼마나 많은 시간이 지났는 지를 다양한 형태, 단위 등으로 반환하는 것인데 바로 그 특정 시점을 의미한다.
Instant 의 경우 별다른 TimeZone 설정은 없지만 기본적으로 에포크타임(=EPOC Time) 이 기준 시점인 것이고, TimeZone 을 통해 그 기준시점을 정해주면 그로부터 에포크타임 간의 시차를 결과값에 더해주는 것이다.
우리가 LocalDateTime을 사용하면서 별도로 TimeZone을 설정해주지 않으면, 아래와 같이 기본 TimeZone을 정한다.
LocalDateTime 의 Default TimeZone 설정
OS로 부터 user.timezone 속성을 불러와서 그 정보를 반환할 시간 값에 보정하여 반환하는 것이다. 이렇게 하면 이제 정상적으로 내 PC (Window 11) 환경의 시간과 일치하는 시간을 반환한다.
그런데또 문제가 생겼다. EC2 인스턴스에 배포를 한 후에 다시 test를 진행해보니 여전히 시간이 9시간 전으로 반환되는 것이였다. 아뿔싸! EC2 인스턴스의 시차가 어떤지를 생각하지 못한 것이다. 이 문제는 아직 정확히 모르겠다. EC2를 생성할 때 서울 리젼으로 생성 했을텐데? 그럼 Linux Ubuntu 환경에서 자동으로 시차가 바뀌는 거 아닌가? 그건 아닌 것 같다. 그저 이미지를 사용해서 인스턴스를 생성하는 것 뿐인 것 같다. 이 문제는 나중에 한번 더 조사해봐야겠다.
하여튼 그래서 직접 TimeZone을 설정해줄 필요가 있었다.
다양한 방법이 있을 것이다. 그저 하드코딩으로 시차를 더해주는 방식이나, ZonedDateTime 이라는 객체는 생성할 때 TimeZone에 대한 정보를 넘겨주면 해당 TimeZone에 맞는 시간을 보여준다고 한다. LocalDateTime은 안되는건가?
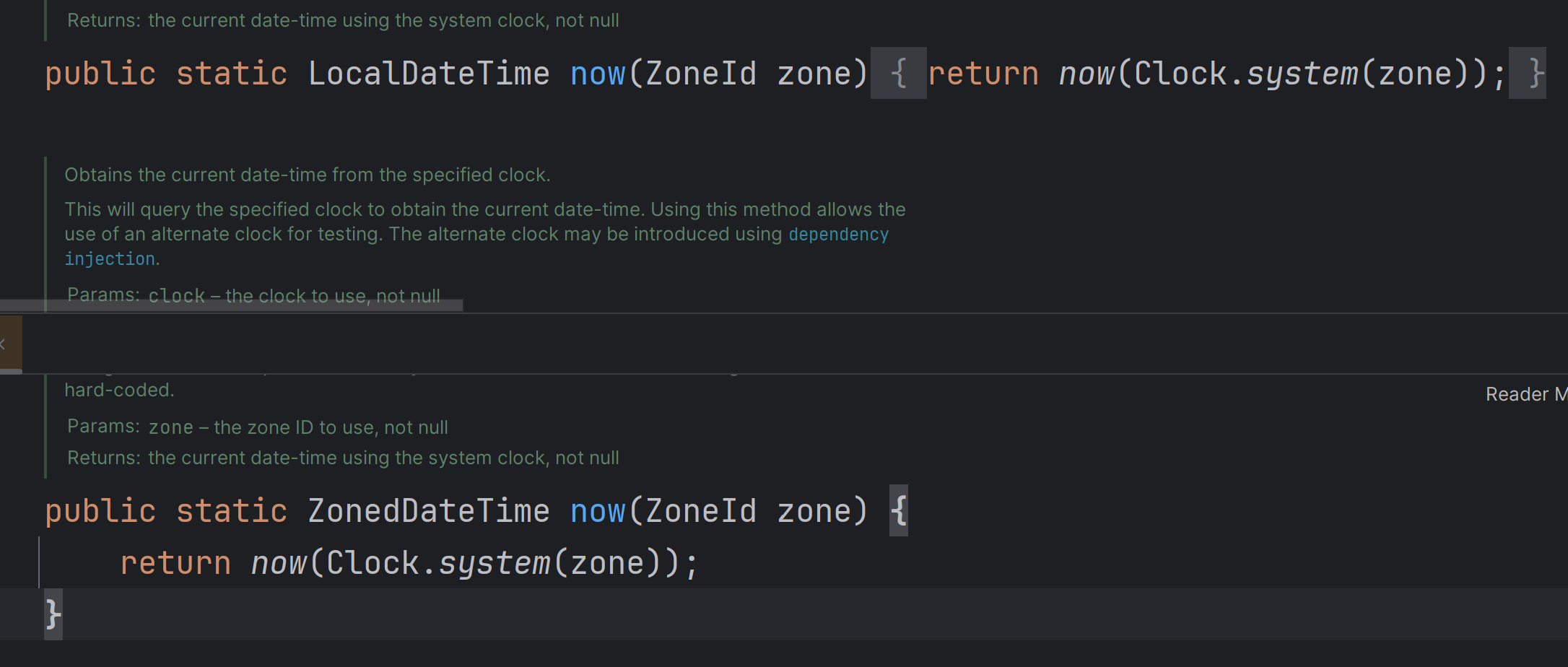
그래서 코드를 뜯어봤더니
왓? 뭐가 다른거지...
아직은 둘이 뭐가 다른건지 잘 모르겠다... 세부적으로 다른 게 분명히 있겠지만 내가 찾아볼 수 있는 수준에서는 다름을 느끼지 못해서 LocalDateTime을 계속 사용하기로 하였고 그럼 그래서 시차를 어떤 식으로 설정 해줘야될까?
now 메서드를 실행할 때마다 Service 레벨에서 ZoneId 를 직접 넘겨줄 수도 있겠지만 우리 서비스는 대한민국에서만 사용될 서비스이기 때문에 시차 설정은 서버가 실행되는 순간 그때 한번이면 된다.
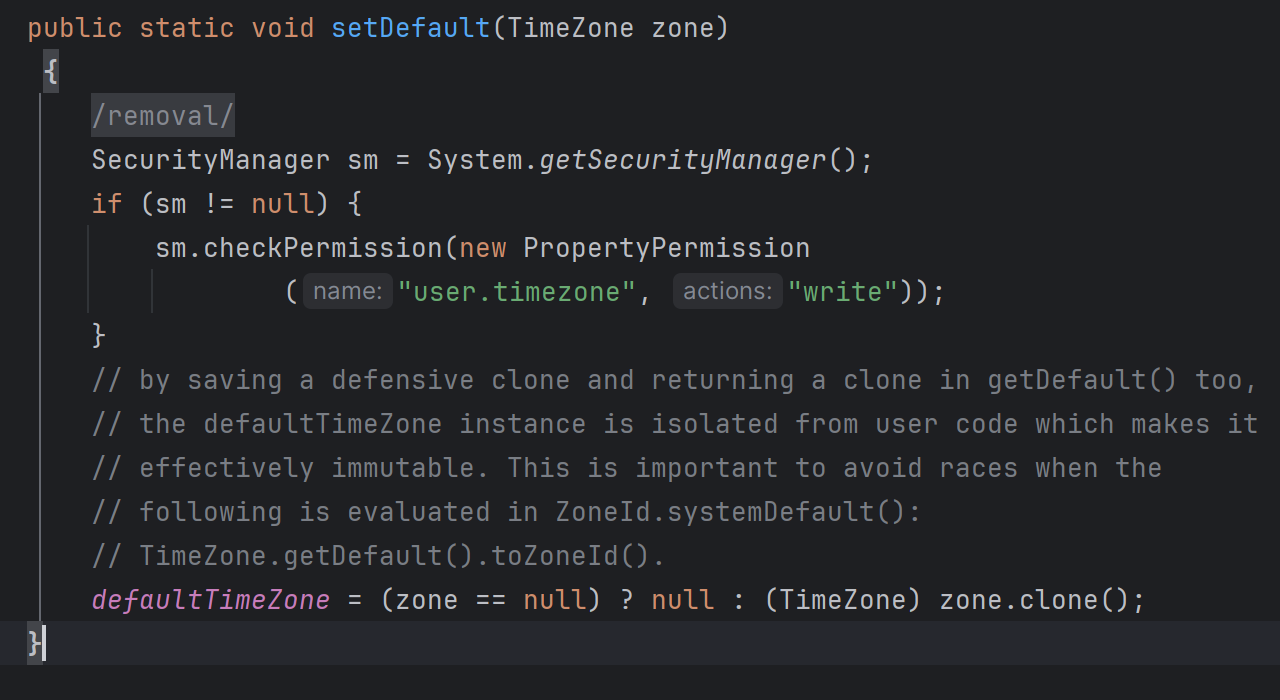
TimeZone 의 setDefault 메서드 TimeZone 을 임의로 설정해 줄 수 있다.
그래서 서버가 실행되는 그 순간 한번 TimeZone 의 setDefault 메서드를 활용하여 TimeZone을 설정해주면 된다.
그래서 2가지 방법을 생각해봤다.
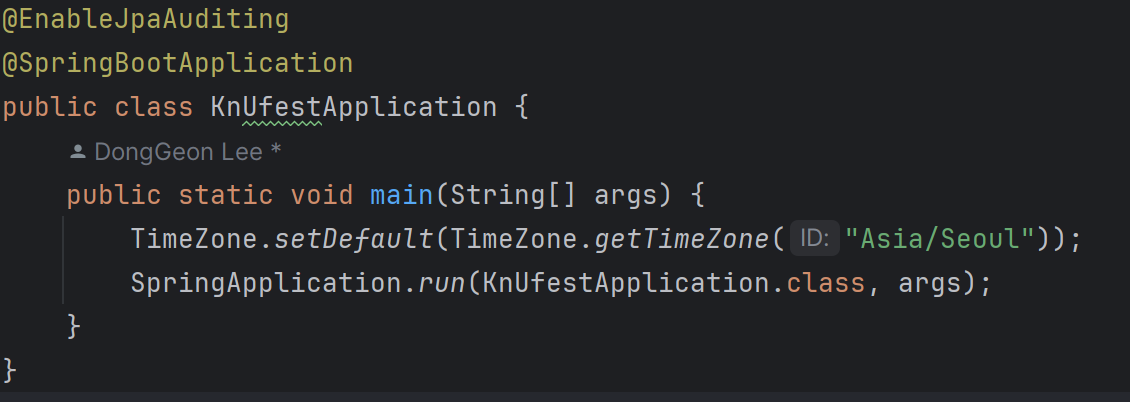
1. SPA(스프링부트애플리케이션) 객체의 main 메서드 내부에서 run 메서드 전에 실행
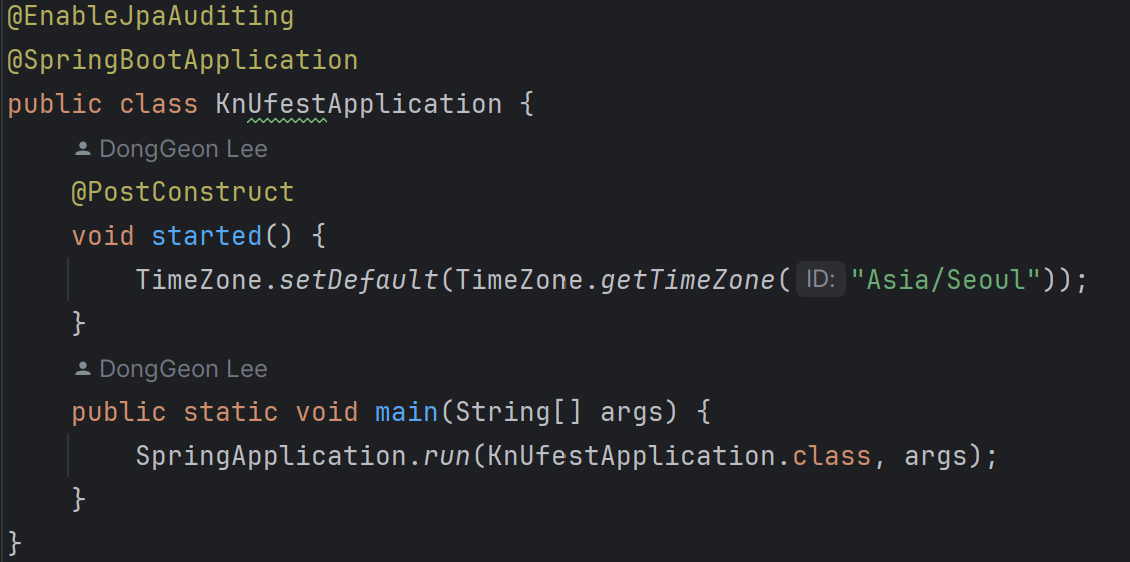
2. @PostConstruct 를 통해 SPA 객체 빈이 완성되는 순간 실행
1. SPA 객체 main 메서드 내부에서 run 메서드 전에 실행
2. @PostConstruct 를 통해 SPA 객체 빈이 완성되는 순간 실행
@PostConstruct 에 대해 잠깐 설명하면 스프링 컨테이너가 해당 객체를 완벽히 생성(의존 주입 완료) 하자마자 바로 자동으로 해당 메서드를 실행시켜줄 수 있게 하는 어노테이션이다.
위 2방법 중에서 고민하다가 큰 차이는 없겠지만 SPA 객체가 생성될 때는 별다른 의존주입이 필요가 없고, 서버가 동작하는 순간이 SpringApplicaiton.run 메서드의 실행이지 해당 객체가 생성되어 스프링 컨테이너에 의해 관리되는 그 시점이 아니기 때문에 그냥 1번 방법을 선택하기로 했다.
의미있는 고민은 아닌 것 같다. 그냥 더 깔끔해보이고 자기 스타일에 맞는 방법을 선택하면 될 것 같다.
그래서 결론은
- 단순히 DB에 timestamp 로써 저장을 한다거나 복잡하고 정교한 비교 등의 연산이 필요한 경우 좀 더 가볍고 정교한 Instant 가 필요하다. 시차를 적용하여 저장해야 한다면, 연산이 끝난 뒤에 atZone 메서드를 통해 ZoneId를 넘겨주어 이를 ZonedDateTime 으로 원하는 시차를 적용하여 변환할 수 있다.
- 일반적으로 우리나라에서만 서비스하는 경우 LocalDateTime 을 사용하여 서버 전체에 시차를 한번만 설정해주는 것이 제일 편한 것 같다.
- 여러 나라에서 서비스 해야한다면, now 메서드를 실행할 때 ZoneId 를 넘겨주어 여러 개의 시차를 적용할 수 있을 것이다. 그때는 LocalDateTime 이나 ZonedDateTime 뭐 아무거나 써도 될 것 같다. (아직 크게 다른 점을 모르겠다...)